Amlogic A311D includes the Verisilicon VIP Nano NPU with 5TOPS+ of computational performance. The fixed and programmable functional units are designed to accelerate specific neuro network functions.
Currently, the NPU is driven with proprietary toolchains that work with very specific vendor SDKs.
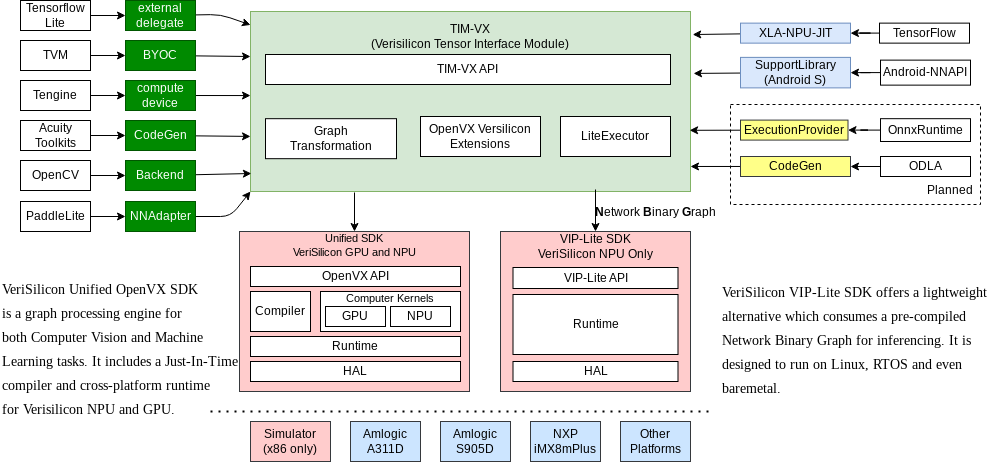
Verisilicon provides the Tensor Interface Module or TIM-VX: GitHub - VeriSilicon/TIM-VX: VeriSilicon Tensor Interface Module
Amlogic provides a Amlogic Neuro Network SDK: Amlogic-NN · GitHub
Tomeu’s work on an upstream open source Mesa stack that will be shipped with various distributions and build toolchains like buildroot and Yocto. For instructions on getting the NPU to work with upstream Mesa, see our TFlite guide.
Amlogic provided example models: AML_NN_SDK/Model/DDK6.4.8.7/A311D_0x88 at master · Amlogic-NN/AML_NN_SDK · GitHub
Some potential applications of the NPU include the following:
Image classification:
- MobileNetV1 is supported already with decent performance.
- MobileNetV3 needs some extra functionality in operations that are already supported.
- InceptionV4 can be supported with additional work:
- Support MaxPool and AvgPool
- Support tensor concatenation
Object detection:
- SSDLite MobileDet is supported already with decent performance with a potential 3x upllift.
Pose estimation:
- PoseNet MobileNet V1: Pretty easy, as the backbone is MobileNet V1.
- MoveNet.SinglePose.Lightning: Quite a few new ops: Sub, FloorDiv, Mul, ArgMax, Cast, Sqrt, …
Audio classification:
- YamNet: The core is fine, but at the beginning there is quite a bit
of tensor massaging with operations we don’t support yet. It may be
fine with just letting those operations run on the CPU.
Depth estimation:
- MiDaS: Only ResizeBilinear is new, rest should be supported.
Super resolution:
- Enhanced Super Resolution GAN: LeakyRelu, Mul, Tensor concatenation. There is a huge number of layers, so probably cannot run in real time.